De Apache a V8 Isolates
Hay varias formas de servir HTML estático para una red local. Te explico las opciones más prácticas:
Opciones principales
1. Nginx (recomendado para producción local)
Es la opción más robusta y eficiente para servir estáticos:
1
sudo apt install nginx
Configura un virtual host en /etc/nginx/sites-available/mi-cdn:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
server {
listen 8080;
server_name 0.0.0.0;
root /var/www/mi-cdn;
index index.html;
# Cache headers para comportamiento CDN
location ~* \.(html|css|js|png|jpg|svg|woff2)$ {
expires 30d;
add_header Cache-Control "public, immutable";
add_header Access-Control-Allow-Origin "*";
}
gzip on;
gzip_types text/html text/css application/javascript;
}
Luego activa y arranca:
1
2
sudo ln -s /etc/nginx/sites-available/mi-cdn /etc/nginx/sites-enabled/
sudo systemctl restart nginx
2. Python HTTP server (para desarrollo rápido)
Sin instalar nada extra:
1
2
cd /ruta/a/tu/html
python3 -m http.server 8080 --bind 0.0.0.0
Accesible desde cualquier dispositivo de la red en http://TU_IP:8080.
3. Caddy (alternativa moderna a Nginx)
Más simple de configurar, con compresión y headers automáticos:
1
sudo apt install caddy
Caddyfile:
1
2
3
4
5
6
:8080 {
root * /var/www/mi-cdn
file_server
encode gzip
header Access-Control-Allow-Origin *
}
Consideraciones importantes
Encontrar tu IP local:
1
ip addr show | grep "inet " | grep -v 127.0.0.1
Firewall: asegúrate de abrir el puerto:
1
sudo ufw allow 8080
Si quieres simular un CDN real (múltiples nodos), puedes poner un HAProxy o Nginx upstream frente a varios Nginx que sirven los mismos archivos, pero para uso interno generalmente un solo nodo Nginx es más que suficiente.
Cuál elegir
| Caso | Opción |
|---|---|
| Desarrollo rápido | Python HTTP server |
| Producción local / blog | Nginx |
| Configuración mínima | Caddy |
Qué es un CDN
Un CDN es una red de servidores distribuidos geográficamente que guardan copias de tus archivos. En lugar de que todos los usuarios del mundo hablen con tu servidor central, hablan con el servidor más cercano a ellos.
1
2
3
4
5
6
7
8
9
Sin CDN:
Usuario en Madrid ──────────────────── Servidor en Virginia
Usuario en Tokyo ──────────────────── Servidor en Virginia
Usuario en Brasil ──────────────────── Servidor en Virginia
Con CDN:
Usuario en Madrid ── Nodo CDN en Madrid ──┐
Usuario en Tokyo ── Nodo CDN en Tokyo ──┼── Origen en Virginia
Usuario en Brasil ── Nodo CDN en Brasil ──┘
El servidor en Virginia sigue existiendo — es el origen. Pero la mayoría de peticiones nunca llegan allí.
Cómo funciona el caching
La primera vez que alguien pide https://tusitio.com/imagen.jpg:
- El nodo CDN más cercano recibe la petición
- No tiene la imagen en caché → la pide al origen (Virginia)
- La guarda en su caché local
- La sirve al usuario
La segunda vez (otro usuario en la misma región):
- El nodo CDN recibe la petición
- Tiene la imagen en caché → la sirve directamente
- El origen nunca se entera
Esto se controla con cabeceras HTTP como Cache-Control: max-age=31536000 (cachea durante un año) o Cache-Control: no-store (nunca cachees esto).
Los principales CDNs del mercado
Cloudflare — el más grande del mundo por número de peticiones. Gratuito en el tier básico, lo que lo hace omnipresente. Sus nodos están en más de 300 ciudades.
Fastly — preferido por empresas grandes (GitHub, Stripe, New York Times). Permite purgar caché en milisegundos, lo que es crítico para sitios de noticias.
AWS CloudFront — integrado con el ecosistema Amazon. Si ya usas S3, EC2 o Lambda, CloudFront es la opción natural.
Akamai — el CDN más antiguo (1998), dominante en grandes corporaciones y streaming de video. Redes de telecomunicaciones, bancos, gobiernos.
Vercel Edge Network — es básicamente Cloudflare por debajo, con una capa de abstracción propia de Vercel.
Qué se puede cachear y qué no
Aquí está la sutileza importante:
Fácil de cachear (cambia poco o nunca):
- Imágenes, videos, fuentes
- Archivos CSS y JS (con hash en el nombre:
main.a3f8c2.js) - HTML estático de un blog o docs
Difícil o imposible de cachear:
- Páginas con contenido personalizado (“Hola, Joan”)
- Carritos de compra
- Dashboards con datos en tiempo real
- Respuestas de APIs con datos que cambian cada minuto
Esto conecta directamente con el debate SSG vs SSR: el HTML estático es perfectamente cacheable en CDN, el HTML generado por SSR normalmente no lo es (o tiene una ventana de caché muy corta).
SSG, SSR
SSG (Static Site Generation) en tiempo de build, el framework genera HTML estático puro. El resultado es un conjunto de archivos .html que se sirven directamente desde un CDN sin ningún servidor. Velocidad máxima, sin cold starts, SEO perfecto. Es ideal para blogs, documentación y sitios de contenido que no cambian frecuentemente.
SSR (Server-Side Rendering) es el modo donde cada petición del usuario activa una función en el servidor (o en el edge) que genera el HTML al vuelo. Permite contenido dinámico, autenticación, personalización en tiempo real.
La relación CDN → Edge Computing
El edge computing es, conceptualmente, la evolución natural del CDN. Un CDN tradicional solo sirve archivos estáticos — es pasivo. El edge computing añade la capacidad de ejecutar código en esos mismos nodos distribuidos.
1
2
CDN clásico: nodo distribuido → solo sirve archivos
Edge Computing: nodo distribuido → sirve archivos + ejecuta código
Cloudflare Workers es exactamente eso: la red CDN de Cloudflare, pero ahora cada nodo puede ejecutar tu JavaScript (via isolates V8) además de servir archivos. Es la misma infraestructura física, con capacidades mucho mayores.
Era Apache (1995 – 2000s)
Apache HTTP Server nació en 1995 y dominó la web durante más de una década. Su modelo era process-based: cada request abría un proceso (o hilo) del sistema operativo. Funcionaba bien con pocas conexiones concurrentes, pero tenía un problema estructural conocido como el C10K problem — manejar 10.000 conexiones simultáneas era prácticamente imposible porque cada una consumía memoria y CPU de forma lineal.
Su configuración con .htaccess era flexible pero cara en rendimiento, porque Apache relía el archivo en cada request.
El problema que cambió todo: C10K (1999)
Dan Kegel publicó en 1999 el paper “The C10K Problem” que básicamente dijo: los servidores web del momento no pueden escalar así. El modelo de un proceso/hilo por conexión no sirve para internet moderno.
Esto catalizó una nueva generación de servidores.
Nginx entra al juego (2004)
Igor Sysoev, un ingeniero ruso, creó Nginx específicamente para resolver C10K. Su arquitectura es radicalmente distinta: event-driven, asíncrono, non-blocking. Un solo proceso worker puede manejar miles de conexiones simultáneas usando el loop de eventos del kernel (epoll en Linux, kqueue en BSD).
Nginx no “espera” a que un request termine — mientras un request espera datos de disco o de una app backend, el worker atiende otros. Esto lo hace extremadamente eficiente en memoria y CPU.
Además, Nginx brilló como reverse proxy y load balancer, roles que Apache hacía mal.
La era de los CDNs reales (2000s)
Paralelamente, Akamai (fundada en 1998) ya estaba construyendo la primera red CDN real: miles de servidores distribuidos geográficamente. La idea es simple pero poderosa — en vez de que todos los usuarios del mundo hagan requests a un servidor en un datacenter, el contenido estático se replica en nodos cercanos a cada usuario.
Llegaron después Cloudflare (2010), Fastly (2011), CloudFront de AWS (2008). Todos usan Nginx u otras soluciones event-driven internamente.
Node.js y el event loop en la app (2009)
Ryan Dahl creó Node.js llevando el modelo asíncrono/event-driven de Nginx al lado de la aplicación. Ya no era solo el servidor web el que era async — toda la lógica de negocio podía serlo. Esto democratizó el modelo de alta concurrencia.
HTTP/2 y HTTP/3 (2015 / 2020)
HTTP/1.1 era el protocolo de Apache: una request por conexión TCP (con keep-alive como parche). Creaba el problema de head-of-line blocking.
HTTP/2 (2015) introdujo multiplexing: múltiples requests en paralelo sobre una sola conexión TCP. Nginx y otros lo adoptaron rápido.
HTTP/3 (2020, estandarizado 2022) reemplaza TCP por QUIC (UDP + confiabilidad en capa de aplicación). Elimina el head-of-line blocking a nivel de transporte y mejora dramáticamente conexiones en redes móviles o con pérdida de paquetes. Cloudflare y Google lo impulsan fuerte.
Contenedores y la muerte del servidor “instalado” (2013+)
Docker (2013) cambió el paradigma: ya no instalas Nginx en tu máquina — corres un contenedor. Nginx oficial tiene imagen Docker. Esto permitió que el servidor web sea efímero, replicable, versionado.
Kubernetes (2014) llevó esto a otro nivel: puedes tener 50 pods de Nginx corriendo, auto-escalar según tráfico, y un ingress controller (que internamente es Nginx o Envoy) rutea el tráfico.
Docker y Kubernetes son dos tecnologías fundamentales en el desarrollo moderno de software (especialmente en 2026), pero resuelven problemas diferentes. La analogía más clara y usada es esta:
- Docker → es la caja (el contenedor)
- Kubernetes → es el puerto / la naviera que organiza miles de cajas
¿Qué es Docker? (explicación sencilla)
Docker es una plataforma que permite empaquetar una aplicación junto con todo lo que necesita para funcionar (código, librerías, dependencias, configuraciones, etc.) dentro de un contenedor.
Un contenedor es como una caja muy ligera que contiene tu aplicación y funciona igual en:
- Tu laptop (Windows, Mac, Linux)
- El servidor de un compañero
- La nube (AWS, Azure, Google Cloud)
- El celular de producción
Ventajas principales de Docker
- “Funciona en mi máquina” → desaparece casi por completo
- Inicio en segundos (no minutos como una VM)
- Muy eficiente en recursos (comparado con máquinas virtuales)
- Fácil de compartir (subes la imagen a Docker Hub, GitHub Container Registry, etc.)
- Docker Compose → permite levantar fácilmente aplicaciones con varios servicios (frontend + backend + base de datos)
Ejemplo realista
Una aplicación típica hoy en día:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# docker-compose.yml
services:
web:
image: mi-empresa/frontend:latest
ports:
- "3000:3000"
api:
image: mi-empresa/backend:latest
environment:
- DATABASE_URL=...
db:
image: postgres:16
volumes:
- db-data:/var/lib/postgresql/data
Con un solo comando (docker compose up) tienes toda la app corriendo localmente.
¿Qué es Kubernetes? (K8s)
Kubernetes es un sistema de orquestación de contenedores open-source (originalmente creado por Google).
Sirve para gestionar cientos o miles de contenedores en producción de forma automática y confiable.
¿Qué problemas resuelve Kubernetes?
| Situación | Sin Kubernetes | Con Kubernetes |
|---|---|---|
| Tienes 5 contenedores de frontend | Tienes que crearlos a mano | Kubernetes los crea automáticamente |
| Uno de los pods se cae | Alguien debe reiniciarlo manualmente | Kubernetes lo detecta y lo reinicia solo |
| De repente hay 10× más tráfico | ¿Más servidores? ¿Cuándo? | Auto-escalado horizontal automático |
| Quieres actualizar la versión | Riesgo de downtime | Rolling update → cero o casi cero downtime |
| Tienes 50 servidores | ¿En cuál corre cada cosa? | Kubernetes decide y balancea la carga |
Conceptos clave de Kubernetes (muy simplificados)
- Pod → la unidad más pequeña (normalmente 1 contenedor, a veces 2–3 que siempre van juntos)
- Deployment → describe cuántos pods quiero y cómo actualizarlos
- Service → da una IP estable y balanceo de carga a los pods
- Ingress → maneja el tráfico HTTP/HTTPS desde fuera (como un reverse proxy inteligente)
- Namespace → como “carpetas” para separar entornos (dev, staging, prod)
Comparación rápida Docker vs Kubernetes (2026)
| Característica | Docker | Kubernetes |
|---|---|---|
| ¿Qué hace principalmente? | Crea y ejecuta contenedores | Orquesta y gestiona muchos contenedores |
| Escala automática | No (solo manual o con Swarm) | Sí (Horizontal Pod Autoscaler) |
| Self-healing | No | Sí (reinicia contenedores caídos) |
| Uso típico | Desarrollo local + pequeñas apps | Producción, microservicios, gran escala |
| Curva de aprendizaje | Baja – media | Alta |
| ¿Se usan juntos? | Sí — la gran mayoría de clústeres K8s usan contenedores Docker (o compatibles) | |
| Alternativas ligeras a K8s | Docker Swarm, Nomad, Docker Compose en ECS/Fargate |
Resumen en una frase
- Usa Docker para empaquetar y probar tu aplicación de forma consistente
- Usa Kubernetes cuando necesites llevar esa aplicación a producción con alta disponibilidad, escalado automático y gestión de fallos a gran escala
En 2026 la combinación Docker + Kubernetes sigue siendo (de lejos) la más utilizada en empresas medianas y grandes para aplicaciones cloud-native.
Edge computing (2017+)
El siguiente salto: no solo replicar archivos estáticos en CDN, sino correr código en el edge. Cloudflare Workers, Fastly Compute, Vercel Edge Functions. Tu función JavaScript corre en el nodo CDN más cercano al usuario, no en tu servidor central.
Hoy: ¿qué usa quién?
| Rol | Tecnología típica |
|---|---|
| Servidor de archivos estáticos | Nginx, Caddy, S3+CloudFront |
| Reverse proxy / ingress | Nginx, Envoy, Traefik |
| CDN pública | Cloudflare, Fastly, Akamai |
| Edge functions | CF Workers, Vercel, Deno Deploy |
| Desarrollo local | Vite dev server, Python http.server |
El resumen filosófico
Apache resolvió “servir HTML”. Nginx resolvió “escalar conexiones”. Los CDNs resolvieron “latencia geográfica”. HTTP/2-3 resolvió “eficiencia del protocolo”. Los contenedores resolvieron “reproducibilidad del entorno”. El edge resolvió “latencia de la lógica”.
Cada capa ataca un cuello de botella distinto. Y Apache todavía está ahí, con ~20% de cuota de mercado — especialmente en hosting compartido y WordPress.
LAMP (1998 – 2000s)
Linux + Apache + MySQL + PHP fue la combinación perfecta para su época porque era completamente gratis y open source en un momento donde el software de servidor costaba fortunas (IIS + SQL Server + ASP de Microsoft era la alternativa de pago).
El flujo era simple y síncrono:
1
Browser → Apache → PHP (ejecuta, consulta MySQL) → HTML → Browser
PHP era un lenguaje de templating glorificado — mezclabas HTML con lógica en el mismo archivo. Horrible en retrospectiva, pero funcionaba. Y MySQL era ligero, fácil de administrar con phpMyAdmin.
El problema era que todo era blocking: Apache abría un proceso por request, PHP esperaba a MySQL, MySQL respondía, PHP generaba HTML, Apache respondía. Si había 500 usuarios simultáneos, 500 procesos. Memoria agotada.
Las variantes LAMP (2005 – 2010)
Empezaron a aparecer sustituciones en cada letra:
La A (Apache) cambia:
- LEMP — Linux + Nginx + MySQL + PHP. Nginx como reverse proxy pasaba los requests PHP a PHP-FPM (FastCGI Process Manager). Mucho más eficiente.
La M (MySQL) se bifurca:
- MariaDB nació en 2009 cuando Oracle compró MySQL. El creador original (Monty Widenius) hizo un fork. Hoy la mayoría usa MariaDB sin saberlo.
- PostgreSQL ganó terreno para casos más serios — mejor manejo de concurrencia, tipos de datos avanzados, cumplimiento SQL más estricto. Tú ya lo usas con Supabase.
La P (PHP) empieza a tener competencia:
- Python + Django (2005) — “batteries included”, ORM potente, admin automático.
- Ruby on Rails (2004) — convención sobre configuración, revolucionó la productividad del desarrollador.
- Python + Flask (2010) — minimalista, tú lo usas.
El gran quiebre: la separación Frontend/Backend (2010+)
En LAMP, PHP generaba el HTML completo en el servidor. El browser recibía HTML listo.
jQuery (2006) fue el primer indicio de que el frontend quería más poder. Pero el quiebre real fue Backbone.js (2010), luego AngularJS (2010, Google) y finalmente React (2013, Facebook).
La arquitectura cambió radicalmente:
1
2
3
4
5
6
LAMP clásico:
Browser → Servidor → [PHP + MySQL] → HTML completo → Browser
Nueva arquitectura:
Browser → CDN → index.html vacío + JS bundle
Browser → API REST → [Python/Node + PostgreSQL] → JSON → Browser (renderiza)
El servidor dejó de generar HTML. Solo devuelve JSON. El HTML lo construye JavaScript en el browser. Esto nació la era de las SPA (Single Page Applications) y las APIs REST.
La pila moderna equivalente a LAMP
| Rol | LAMP | Hoy |
|---|---|---|
| OS | Linux | Linux / contenedor Docker |
| Web server | Apache | Nginx / Caddy |
| Base de datos | MySQL | PostgreSQL / Supabase |
| Backend | PHP | Python/Flask, Node/Express, Go |
| Frontend | HTML en PHP | Vue, React, Svelte |
| Deploy | FTP al servidor 😅 | Git push → CI/CD → nube |
El deployment: de FTP a CI/CD
En la época LAMP el deployment era literalmente:
- Abrir FileZilla
- Arrastrar archivos al servidor por FTP
- Rezar
Hoy el flujo es:
1
2
3
4
git push → GitHub Actions / GitLab CI →
tests automáticos →
build del frontend →
deploy a servidor / Vercel / Railway / Fly.io
El servidor ni se toca manualmente. Si algo falla, se hace rollback automático al commit anterior.
La era Serverless (2014+)
Amazon Web Services Lambda (2014) introdujo otro modelo: no hay servidor que administrar. Subes una función, se ejecuta cuando la llaman, pagas por ejecución. Escala a cero cuando no hay tráfico.
El equivalente LAMP serverless hoy sería:
- Supabase (PostgreSQL gestionado, tú ya lo usas)
- Vercel / Netlify (frontend estático en CDN global)
- AWS Lambda / Cloudflare Workers (lógica backend)
No instalas nada. No administras servidores. No haces FTP.
Serverless Functions
Serverless no significa “sin servidor” — significa que tú no gestionas los servidores. El proveedor (Vercel, Cloudflare, Netlify…) gestiona todo: escalado, disponibilidad, parcheado. Tú solo escribes funciones que se ejecutan en respuesta a peticiones HTTP.
La gran ventaja es el modelo de pago: pagas por ejecución, no por servidor encendido. La gran desventaja histórica era el cold start: cuando una función lleva tiempo sin ejecutarse, el contenedor tarda unos segundos en arrancar. Cloudflare Workers resuelve esto porque no usa el modelo de contenedores — usa el modelo de isolates de V8, que arrancan en microsegundos.
En el contexto de tu proyecto market-analyze con Flask, estás usando un modelo más tradicional (servidor Vercel con Python runtime). Las serverless functions en Astro serían los API endpoints (.ts files en src/pages/api/) que puedes desplegar como Workers en Cloudflare.
Lo que no cambió
Curiosamente, los conceptos fundamentales siguen igual:
- Sigue habiendo un cliente que hace requests
- Sigue habiendo un servidor que responde
- Sigue habiendo una base de datos relacional
- Sigue habiendo caché para no golpear la DB en cada request
Lo que cambió es dónde corre cada pieza, cómo se comunican, y quién administra la infraestructura.
La complejidad no desapareció — se movió del servidor al proceso de build, al CI/CD, a la configuración de la nube. En LAMP instalabas Apache una vez y te olvidabas. Hoy tienes Dockerfile, docker-compose, variables de entorno, secrets, pipelines… es más potente pero también más piezas móviles.
Ejemplo: que hace Vercel con Flask
Vercel está diseñado para frontend y funciones serverless (Node.js nativamente), pero tiene soporte para Python mediante su Python Runtime. Cuando deployás Flask en Vercel, no está corriendo como un servidor Flask tradicional — Vercel convierte cada request en una invocación serverless.
Lo que realmente ocurre:
1
2
Request → Vercel Edge Network → Python Runtime → tu app Flask → Response
(CDN global) (Lambda-like)
Tu Flask no está “corriendo” esperando requests. Se instancia por request (o se reutiliza si hay una instancia caliente).
Las limitaciones
Tiempo de ejecución: Vercel tiene un límite de 10 segundos en el plan free (60s en Pro) por request. Si tu análisis financiero tarda en calcular retornos o hacer scraping con yfinance, puedes toparte con timeouts.
Cold starts: Si nadie usa la app por un rato, el próximo request tarda más porque Vercel tiene que levantar el runtime de Python desde cero.
Sin estado persistente: No puedes guardar nada en disco ni en memoria entre requests. Cada invocación es efímera — por eso tu SQLAlchemy apunta a Supabase externo y no a SQLite local.
Filesystem read-only: No puedes escribir archivos temporales fácilmente.
Comparado con alternativas para Flask
| Plataforma | Modelo | Free tier | Ideal para |
|---|---|---|---|
| Vercel | Serverless | Generoso | APIs simples, baja concurrencia |
| Railway | Servidor persistente | Limitado | Flask “real”, SQLite, procesos largos |
| Render | Servidor persistente | Sí (con sleep) | Similar a Railway |
| Fly.io | Contenedor | Sí | Control total, más complejo |
| PythonAnywhere | Servidor WSGI | Sí | Flask clásico, muy simple |
La batalla por el mercado: Vercel vs Cloudflare vs Netlify
Todos compiten por ser la plataforma donde los desarrolladores despliegan la web moderna.
Vercel es el creador de Next.js. Su estrategia es análoga a la de Cloudflare con Astro: controlas el framework, controlas el destino de despliegue más natural. Next.js + Vercel es la combinación “golden path”. Han apostado fuerte por el App Router y los React Server Components. Su punto débil: es caro a escala y relativamente cerrado al ecosistema.
Cloudflare tiene la infraestructura más global del mundo y los precios más competitivos. Hasta ahora le faltaba el “framework propio” que actuara como puerta de entrada para desarrolladores. Con Astro, tienen eso. Su punto fuerte: Workers es técnicamente superior en latencia y cold starts.
Netlify fue pionero del JAMstack pero ha perdido terreno. Curiosamente, Netlify es uno de los socios del Astro Ecosystem Fund, lo que muestra que incluso los competidores directos de Cloudflare reconocen que necesitan apoyar el ecosistema Astro para no quedarse fuera del mercado.
AWS Amplify, Firebase (Google), Azure Static Web Apps también compiten en este espacio pero con menos tracción en el mercado de desarrolladores frontend.
La dinámica clave es: quien controla el framework controla el flujo de desarrolladores. Por eso Vercel compró/creó Next.js, Cloudflare compró Astro, y plataformas como Remix (adquirido por Shopify) o SvelteKit (Vercel sponsor) están todas en la misma guerra.
Modelo de Isolates de V8
Para entenderlo bien, hay que partir desde abajo.
El problema con los modelos tradicionales
Cuando Vercel o AWS Lambda ejecutan una serverless function, usan contenedores (básicamente mini-máquinas virtuales). El ciclo es:
- Llega una petición
- El sistema busca si hay un contenedor ya “caliente” con tu función
- Si no lo hay → arranca un contenedor nuevo (instala el OS, el runtime, tu código…)
- Ejecuta la función
- Devuelve la respuesta
Ese paso 3 es el cold start, y puede tardar entre 200ms y varios segundos. Es el talón de Aquiles del serverless clásico.
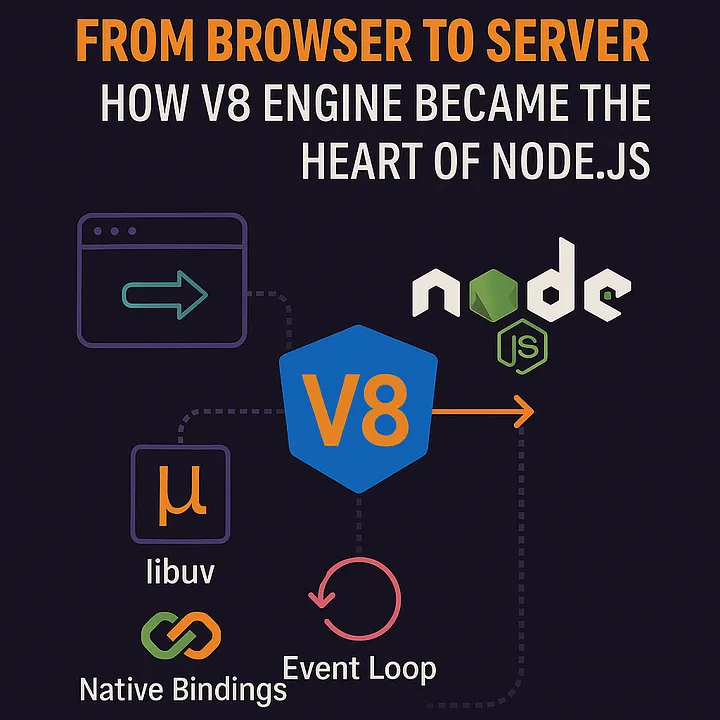
Qué es V8
V8 es el motor JavaScript de Google, el mismo que corre dentro de Chrome y Node.js. Su trabajo es tomar código JavaScript/TypeScript y ejecutarlo de forma eficiente.
Qué es un Isolate
V8 tiene un concepto interno llamado isolate: un entorno de ejecución completamente aislado, con su propia memoria, su propio estado, sin acceso al sistema de archivos ni a otros isolates. Es como una “burbuja” donde corre código JS.
La clave es que crear un isolate es increíblemente barato. No necesitas arrancar un OS, no necesitas un contenedor, no necesitas un proceso nuevo. V8 ya está corriendo en el servidor de Cloudflare — simplemente crea una nueva burbuja aislada en microsegundos, ejecuta tu función dentro, y la destruye.
1
2
Contenedor (Lambda/Vercel) → cold start ~200ms–2s
Isolate (Cloudflare Workers) → cold start ~0–5ms
La analogía
Imagina un teatro. El modelo de contenedores es como tener que construir un teatro nuevo cada vez que alguien quiere ver una obra. El modelo de isolates es como tener un teatro gigante ya construido y simplemente asignar un asiento aislado a cada espectador.
Las limitaciones del modelo
No es todo perfecto. Precisamente porque no hay OS ni filesystem real, los Workers tienen restricciones:
- No puedes usar módulos Node.js nativos que dependan del sistema (como
fs,child_process, o partes decrypto) - Hay un límite de memoria por isolate (128MB por defecto)
- No puedes hacer operaciones bloqueantes largas
Por eso frameworks como Flask (Python) no pueden correr en Workers — Python no es V8. Cloudflare tiene Workers for Python en beta, pero con limitaciones importantes.
¿Son estos contenedores Docker?
Cuando hablamos de serverless functions en plataformas como AWS Lambda, Vercel o Cloudflare, la mayoría usa algún tipo de contenedor o aislamiento ligero, pero no todos usan Docker de la misma forma. Vamos a desglosarlo claramente (datos actualizados a marzo 2026):
Comparación rápida: ¿Qué usa cada uno para aislar/ejecutar funciones serverless?
| Plataforma | ¿Usa contenedores “mini-VM”? | Tecnología principal | ¿Es Docker estándar? | Detalles clave (2026) | Cold start típico | Nivel de aislamiento |
|---|---|---|---|---|---|---|
| AWS Lambda | Sí | Firecracker (microVM de AWS) | No (compatible con imágenes Docker) | Cada función corre en su propia microVM ligera (KVM-based). Boot <125 ms, memoria ~5 MB. Muy seguro para multi-tenant. | ~100–500 ms | Alto (VM-level) |
| Vercel | Sí (Serverless Functions) | Ephemeral containers (en AWS Lambda bajo el capó) | No directamente | Vercel Serverless Functions → corre sobre AWS Lambda (ephemeral Node.js/Python/etc. containers). Edge Functions → V8 isolates (no containers). | Serverless: ~200–1000 ms Edge: <50 ms | Medio (container) / Bajo (V8 isolate) |
| Cloudflare | No (Workers estándar) Sí (Containers beta) | V8 Isolates (para Workers) Firecracker + otros (para Containers) | Sí para Containers (acepta Docker images) | Workers: ultra-ligero, sin contenedores/VMs → isolates V8 (~1 ms cold start). Containers (beta/paid): corre imágenes Docker en Firecracker microVMs globales. | Workers: <1–5 ms Containers: ~10–15 s | Bajo (isolate) / Alto (microVM) |
Explicación detallada
- AWS Lambda
Sí, usa contenedores, pero son microVMs con Firecracker (no Docker runtime tradicional).- Firecracker es un hypervisor ligero (escrito en Rust) que crea mini-máquinas virtuales ultra-rápidas y seguras.
- Puedes subir imágenes Docker (OCI-compatible) y Lambda las convierte internamente a Firecracker.
- Ventaja: aislamiento fuerte (cada función tiene su kernel), ideal para multi-tenant.
- Desventaja: cold starts más notorios que en edge puro.
- Vercel
Depende del tipo de función:- Vercel Edge Functions / Edge Runtime → NO usa contenedores. Corre en V8 isolates (como Cloudflare Workers). Muy rápido, casi cero cold start, pero limitado (solo Web APIs, subset de Node.js).
- Vercel Serverless Functions (las clásicas de
/apio Server Actions en Next.js) → SÍ usa contenedores efímeros, pero bajo el capó es AWS Lambda (ephemeral Node.js containers o similares). Vercel abstrae todo, pero la infra base es AWS → hereda Firecracker/microVMs.
Vercel no soporta deploy directo de Docker (no es un container platform como Cloud Run o Fly.io). Todo se buildea a su runtime propietario.
- Cloudflare
- Cloudflare Workers (el principal) → NO usa contenedores ni VMs. Todo corre en V8 isolates aislados (tecnología de Chrome). Es lo más ligero y rápido del mercado (cold starts sub-milisegundo).
- Cloudflare Containers (beta desde 2025, GA en 2026) → SÍ acepta y corre imágenes Docker. Las ejecuta en Firecracker microVMs (o gVisor en algunos casos) distribuidas globalmente en su red. Perfecto para runtimes pesados (Python full, Go, Rust binarios, etc.) que no caben en Workers.
Resumen simple
- Si oyes “serverless function = mini contenedor/VM”, es cierto en la mayoría (especialmente AWS y Vercel Serverless), pero no siempre es Docker tradicional.
- Docker es más un formato de empaquetado (OCI image) → muchas plataformas lo aceptan como input, pero lo convierten a su runtime interno (Firecracker, gVisor, etc.).
- Cloudflare es la excepción más radical con isolates V8 para la mayoría de casos (sin contenedores), y solo usa microVMs/Firecracker cuando necesitas “contenedores reales” (Containers feature).
En 2026 la tendencia es clara: microVMs ligeros (Firecracker, etc.) + V8 isolates dominan el serverless por seguridad + velocidad, mientras Docker queda más para “container serverless” como Google Cloud Run o Azure Container Apps.